


Building AI applications has become the easy part. Getting them to production is where things fall apart.
The observability gaps, the memory failures, the cost overruns, the integration brittleness are the norm now. And they represent a category-defining opportunity.
This is the middleware moment in AI where the next wave of durable value in AI will be created: in the connective tissue between raw intelligence and real-world deployment.
The framing draws on a familiar pattern from tech history. Apps always precede infrastructure, but infrastructure is what enables them to scale. We've seen it with email and TCP/IP, with Amazon and JavaScript, with ChatGPT and LangChain. We're now at the crossover moment where the first wave of AI apps has created enough complexity that a new generation of middleware needs to be built to support what comes next.
The PoC-to-Production Graveyard

If you have built an AI application for enterprise use, you know this feeling. The demo works. The prototype works. Your internal stakeholders are excited. And then you try to move it into production, and reality arrives.
The natural instinct is to blame the models. They hallucinate. They are inconsistent. They are expensive. All of this is true. But the models are not where deployments die. I have sat through enough post-mortems - with CIOs, CTOs, engineering leads, and founders - to say with confidence that the breakdown mostly happens in the surrounding infrastructure. Here is what actually kills enterprise AI deployments:
Integration Brittleness
Enterprise environments are not clean. They are patchworks of legacy systems - SAP installations that predate most of the engineering team, Salesforce customizations layered over a decade, internal databases with inconsistent schemas, and APIs written by contractors who left in 2018. Raw AI APIs assume you can just feed them data. They cannot navigate this complexity. Every integration requires custom engineering work, and that work breaks every time something upstream changes.
A real example: a large bank spent nine months building an AI assistant for relationship managers. The demo worked beautifully. Production deployment stalled because the CRM, the portfolio management system, and the communication logs each lived in different data silos with different auth protocols and different update frequencies. Integrating them reliably turned out to be harder than the AI itself.
The Statelessness Problem
Today's enterprise AI is almost entirely stateless. Every conversation starts from zero. The model does not know what happened in the last session, what the user's preferences are, what decisions were made last week, or what context accumulated over months of prior interactions.
But Enterprise workflows are inherently stateful - a procurement approval depends on prior context, a customer service interaction builds on prior history, a research workflow accumulates knowledge over time. Without persistent memory, AI cannot participate meaningfully in these workflows. It becomes a sophisticated autocomplete tool rather than a genuine work colleague.
Cost as a Runaway Variable
AI infrastructure costs have become the budget surprise of the decade. A proof-of-concept running 50 queries a day in development looks entirely different from a production system handling 50,000 queries. But most teams do not discover this until they are already committed to the architecture.
The problem compounds in agentic deployments. When an agent runs a 15-step reasoning chain to answer a single question, the token cost per interaction can be 10x what the team modeled. Without intelligent routing - sending simple queries to cheaper models, caching repetitive retrievals, batching low-priority requests - costs spiral quickly. We have seen startups burn through their entire 6-month runway in 12 weeks because their agent architecture was cost-unaware.
Observability Blindness
When a traditional software system fails in production, you have logs. You know exactly what happened, at what time, with what inputs. When an AI agent fails, you typically have a wrong output and no idea why. Did it retrieve the wrong context? Did the model misinterpret the prompt? Did a tool call return unexpected data? Did a multi-step chain fail halfway through? Most production AI deployments today have no meaningful observability infrastructure, which means they cannot debug failures, cannot improve over time, and cannot satisfy enterprise-grade reliability requirements.
Hallucination at Scale
A 2% hallucination rate sounds tolerable in a demo. At production scale, it means thousands of wrong answers per day. In a customer-facing application, each one is a potential trust-breaking incident. In a healthcare workflow, each one is a patient safety risk. In a financial services context, each one is a potential compliance violation. Guardrails, output validation, and graceful degradation are not nice-to-haves - they are production requirements that models do not natively provide.
The hard truth: These failures are not accidents. They are the predictable result of deploying powerful models without the surrounding infrastructure that makes them production-safe.
The Layer in Between
The word "middleware" is old enough to be imprecise. In the context of AI, I use it to mean something specific: the infrastructure layer that sits between the foundation models and the real end user applications that enterprises actually use - handling everything that makes models production-ready at scale.
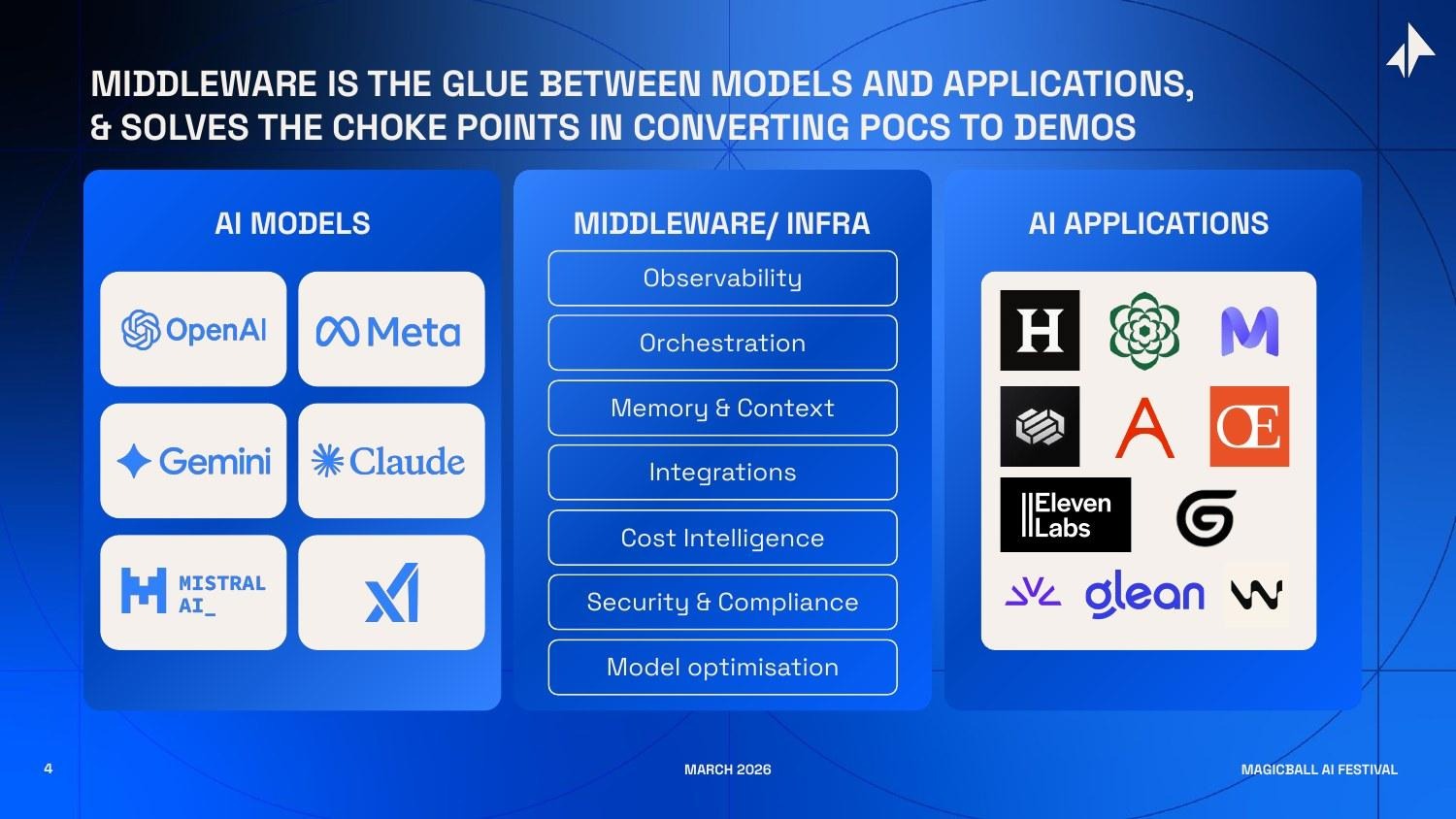
Visualize the AI stack as three horizontal layers.
At the bottom: foundation models - OpenAI, Anthropic, Google DeepMind, Meta, Mistral, xAI, and the growing roster of open-weight alternatives.
At the top: AI applications - Glean for enterprise search, Harvey for legal, Sierra for customer service, Writer for content, and thousands of vertical-specific tools being built right now.
In the middle: the infrastructure that makes the bottom layer usable by the top layer.
That middle layer is not a single product. It's a set of interlocking capabilities, each solving a distinct production challenge:
- Observability & Tracing: Logging every step of every AI interaction - inputs, outputs, tool calls, latencies, costs, errors - in a format that engineers can debug and compliance teams can audit.
- Orchestration: Managing multi-step AI workflows - sequencing tool calls, handling retries, routing between models, managing parallel execution, and coordinating multi-agent systems.
- Memory & Context Management: Giving AI systems the ability to remember - user preferences, prior conversation history, accumulated domain knowledge, and enterprise-specific context that makes responses useful rather than generic.
- Integrations: Connecting AI systems to the enterprise data and tool ecosystem - CRMs, ERPs, databases, communication tools, internal APIs - through standardized interfaces that survive system changes.
- Cost Intelligence: Routing queries to the right model at the right cost, caching repetitive retrievals, batching low-priority requests, and providing CFO-grade visibility into AI spend.
- Security & Compliance: Enforcing data governance policies, managing access controls, providing audit logs, sanitizing sensitive data before it reaches models, and ensuring deployment meets regulatory requirements.
- Evaluation & Quality: Systematically measuring whether AI outputs are accurate, consistent, and safe - through automated testing, human-in-the-loop review, and continuous monitoring in production.
Each of these is a genuine, non-trivial engineering problem. Each has spawned - or is spawning dedicated companies. And together, they constitute the middleware layer that will determine whether enterprise AI actually delivers on its promise.
App<>Infrastructure<>App<>Infrastructure
Before making the forward-looking case, it is worth grounding this in history. Because the pattern I am describing - application wave followed by infrastructure wave sinusoidally - is not new. It has repeated, with remarkable consistency, through every major platform transition in computing.

The cloud computing era produced some of the most valuable infrastructure companies of the last two decades. Stripe took the complexity of global payments - a maze of banking relationships, fraud detection, tax compliance, and currency conversion - and collapsed it into a few lines of code. Twilio made communication APIs so simple that any developer could build calling and messaging into any product. Databricks made it possible to run data analytics pipelines at scale without managing the underlying infrastructure. Snowflake commoditized the data warehouse. Combined, these companies created roughly $400 billion in market value. They did not win by having the most interesting technology - they won by solving the hardest operational problems so that application developers did not have to.
The insight I find most useful comes from a simple observation: transformative applications almost always precede the infrastructure that enables them at scale. The light bulb was invented before there was an electric grid. Planes were flying before commercial airports existed. The automobile preceded paved roads, gas stations, and traffic laws by decades. In each case, the technology worked in limited demonstrations long before the surrounding infrastructure made it accessible to the mass market.
This matters because it tells us that the infrastructure wave is not speculative - it is the predictable, necessary consequence of application adoption. The question is never whether the infrastructure will be built. The question is who builds it, and when.
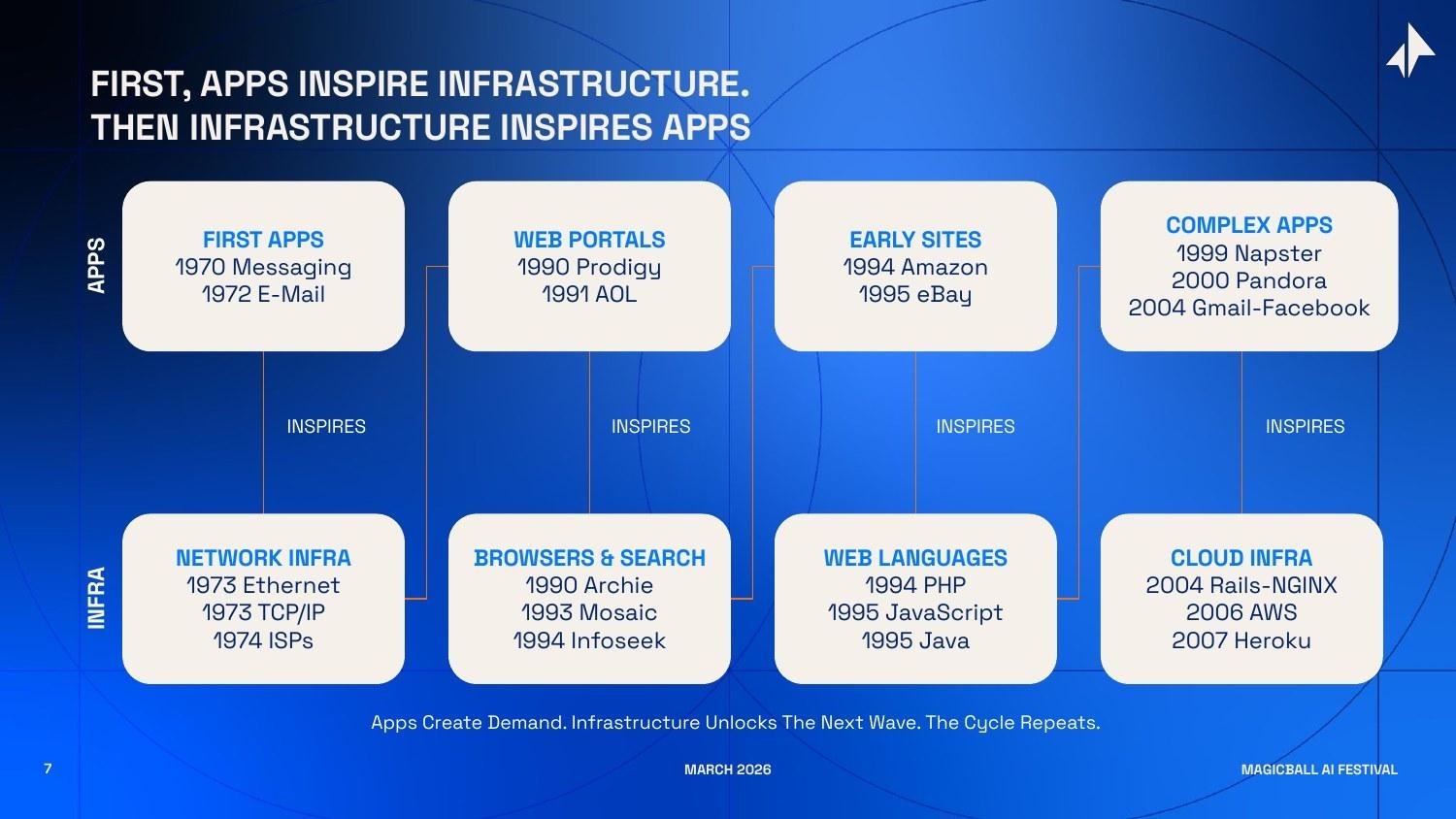
Tracing the pattern through the internet era:
- Early messaging and email (apps) revealed the need for reliable data transmission, inspiring Ethernet (1973), TCP/IP (1973), and the first ISPs (1974).
- Web portals and early e-commerce (apps) revealed the need for information retrieval and web development tools, inspiring Archie (1990), Mosaic (1993), PHP (1994), and JavaScript (1995).
- Web 2.0 applications - Gmail, Facebook, YouTube (apps) revealed the need for elastic, scalable compute, inspiring AWS (2006), Rails (2004), and Heroku (2007).
- Mobile applications (apps) revealed the need for analytics, payments, and authentication at mobile scale, inspiring Stripe (2011), Mixpanel (2009), and Firebase (2011).
At each inflection point, the companies that built the picks-and-shovels layer captured as much value as the most successful applications running on top of them. AWS became more valuable than most of the web applications it hosts. Stripe is worth more than most e-commerce companies. Snowflake's market cap exceeded many of the enterprises whose data it manages.
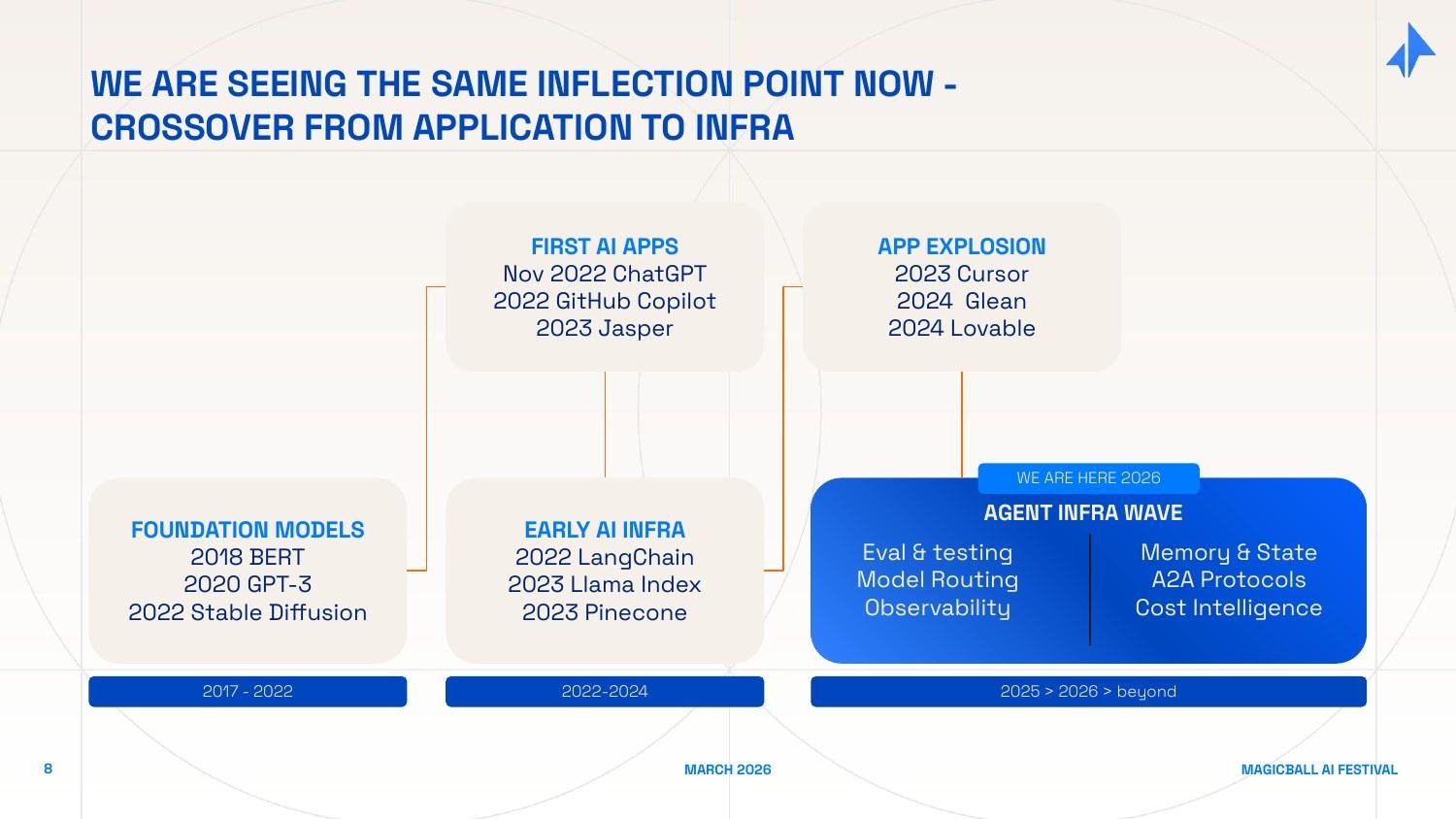
Now look at the AI timeline. ChatGPT (November 2022) was the application moment - the demo that made the underlying technology legible to the mass market. GitHub Copilot proved enterprise willingness to pay. Jasper, Midjourney, and their cohort proved consumer adoption. The 2023-2024 "application explosion" - Cursor, Glean, Lovable, Perplexity, and thousands of vertical AI tools - intensified demand and surfaced the production problems I described earlier.
We are now entering the infrastructure response. The demand signal is undeniable. The winning companies will be the ones that solve these problems first, at scale, with the enterprise trust required for production deployment.
The AI middleware wave is playing out on a platform that is fundamentally larger - touching every industry, every function, and every knowledge worker on the planet.
Why the Window is Right Now
Historical patterns are instructive but not sufficient. The infrastructure wave always comes - but the precise timing matters enormously for investors and founders. Four forces are converging right now to make middleware the most urgent layer in AI.
Force 1: The Agentic Shift - From Questions to Workflows

The most consequential shift in enterprise AI right now is not about better models. It is about AI moving from answering questions to completing work.
Consider the complexity ladder:
- A chatbot (2023) makes a single LLM call. One input, one output, no state. The infrastructure requirements are trivial.
- A RAG-powered copilot (2024) makes 3-5 calls. It retrieves context, injects it into a prompt, calls the model, and returns a response. Manageable, but already requiring prompt management, caching logic, and retrieval quality monitoring.
- A single AI agent (2025) makes 10-50 calls per task. It plans, selects tools, executes steps, checks its own outputs, retries failures, manages state across a multi-step workflow, and tracks costs per interaction. Each step can fail independently. The surface area for failure has multiplied 10x.
- A multi-agent system (2026) makes 100+ calls per workflow. Multiple specialized agents - a planner, domain specialists, a validator - hand off work to each other across model boundaries. Each agent has its own memory, its own tool access, its own error conditions. Observability across the full chain is not optional, it is the only way to know if the system is working.
Most enterprises are just reaching the single-agent tier. The infrastructure decisions made right now - how to orchestrate, how to store state, how to route across models, how to monitor quality - will determine whether these deployments succeed or quietly join the PoC graveyard.
The companies building the orchestration and observability infrastructure for agentic AI are building something analogous to what Apache Kafka built for event-driven systems, or what Kubernetes built for containerized workloads. The complexity is real, the demand is here, and the market has not yet converged on dominant solutions.
Force 2: Multi-Model is the Enterprise Default
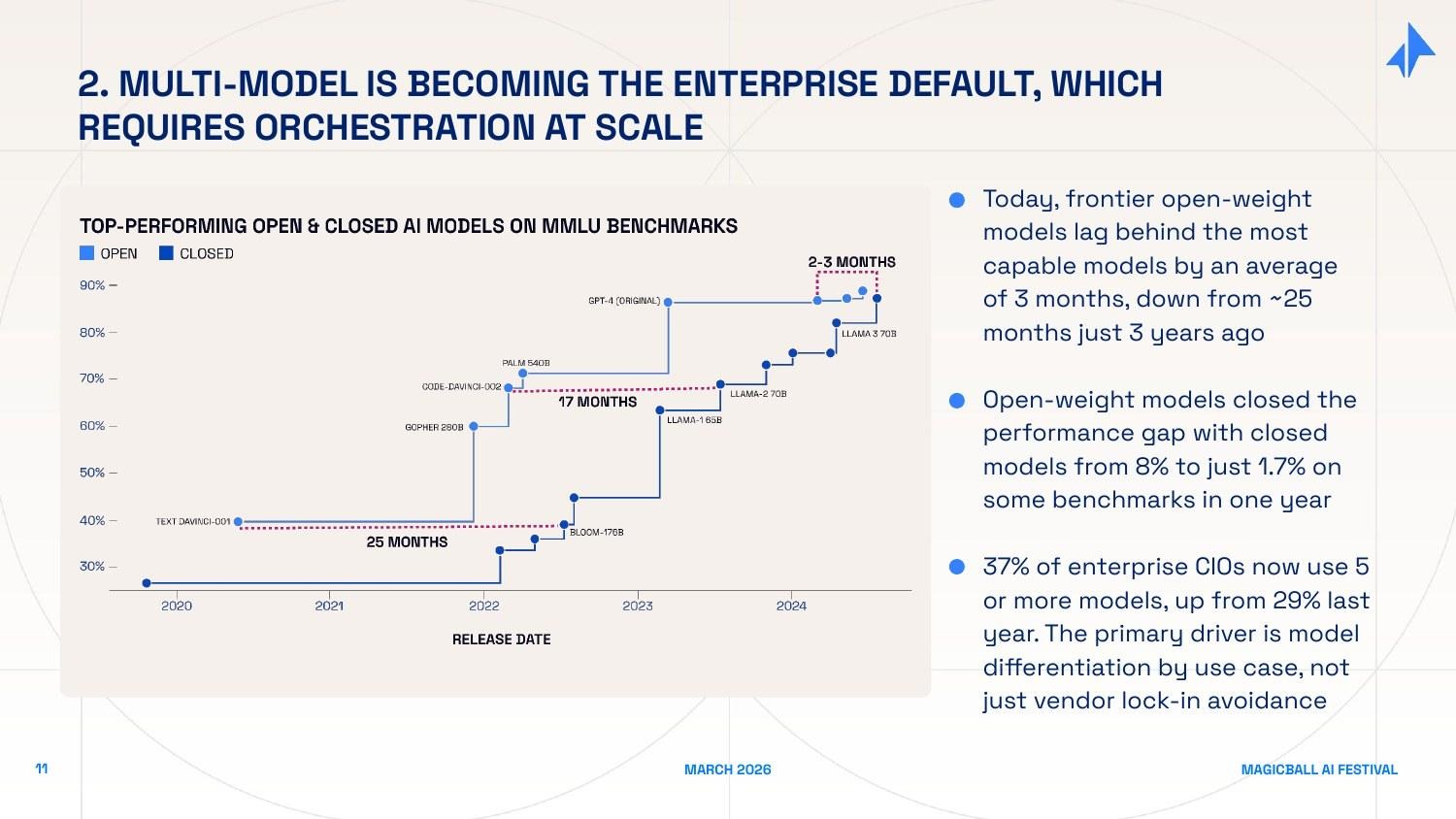
Two years ago, the model landscape was simple: OpenAI was far ahead, and every other option was a distant second. That world no longer exists. Three changes have happened simultaneously:
Open-weight models have closed the gap dramatically. Models that used to lag frontier closed models by 25 months on standard benchmarks now lag by roughly 3 months. The performance gap on some benchmarks has narrowed from 8% to 1.7% in a single year. For many enterprise use cases - coding assistance, document summarization, structured data extraction - open-weight models running on private infrastructure are now genuinely competitive.
Specialization has emerged. No single model is best at everything. Claude Sonnet is better at long-context reasoning and careful instruction-following. GPT-4o has strong multimodal capabilities. Gemini Ultra excels at complex multi-step reasoning over large document sets. Meta's Llama models are fast and cheap for high-volume, lower-complexity tasks. The rational enterprise does not pick one model - it picks the right model for each use case.
This creates a routing and orchestration problem that cannot be solved at the application layer.
An enterprise running five models for five different use cases needs infrastructure that routes queries intelligently - sending the right query to the right model at the right cost, with unified observability across all providers, and a consistent interface that survives model deprecations and provider changes. This is exactly what Portkey, one of our portfolio companies, is building. It is also why LLM gateways and routing layers are now foundational enterprise infrastructure rather than a nice optimization.
Force 3: Cost Has Become a Boardroom Problem

AI has a cost structure that enterprises have not encountered before. Most enterprise software costs are predictable - a SaaS seat, a server, a license. AI inference costs are usage-based, highly variable, and sensitive to factors that engineering teams do not always control: prompt length, response length, model choice, the number of steps an agent takes, and whether retrieval is cached.
Average enterprise AI budgets rose 36% to approximately $85,000 in 2025. Yet 80% of enterprises miss their AI infrastructure cost forecasts by more than 25%. This is not a rounding error - it reflects a genuine absence of cost observability and governance tooling.
More consequentially, AI is on a trajectory to become the largest line item in many enterprise P&Ls - potentially exceeding cloud infrastructure costs, and rivaling salary budgets for knowledge-worker-intensive organizations. AI costs need the same treatment. The companies that build AI FinOps infrastructure - real-time cost attribution by team, use case, and query type; intelligent routing that balances quality and cost; budget guardrails that prevent runaway spend - are solving a problem that every enterprise AI deployment will hit.
Force 4: Agents Have Become Buyers
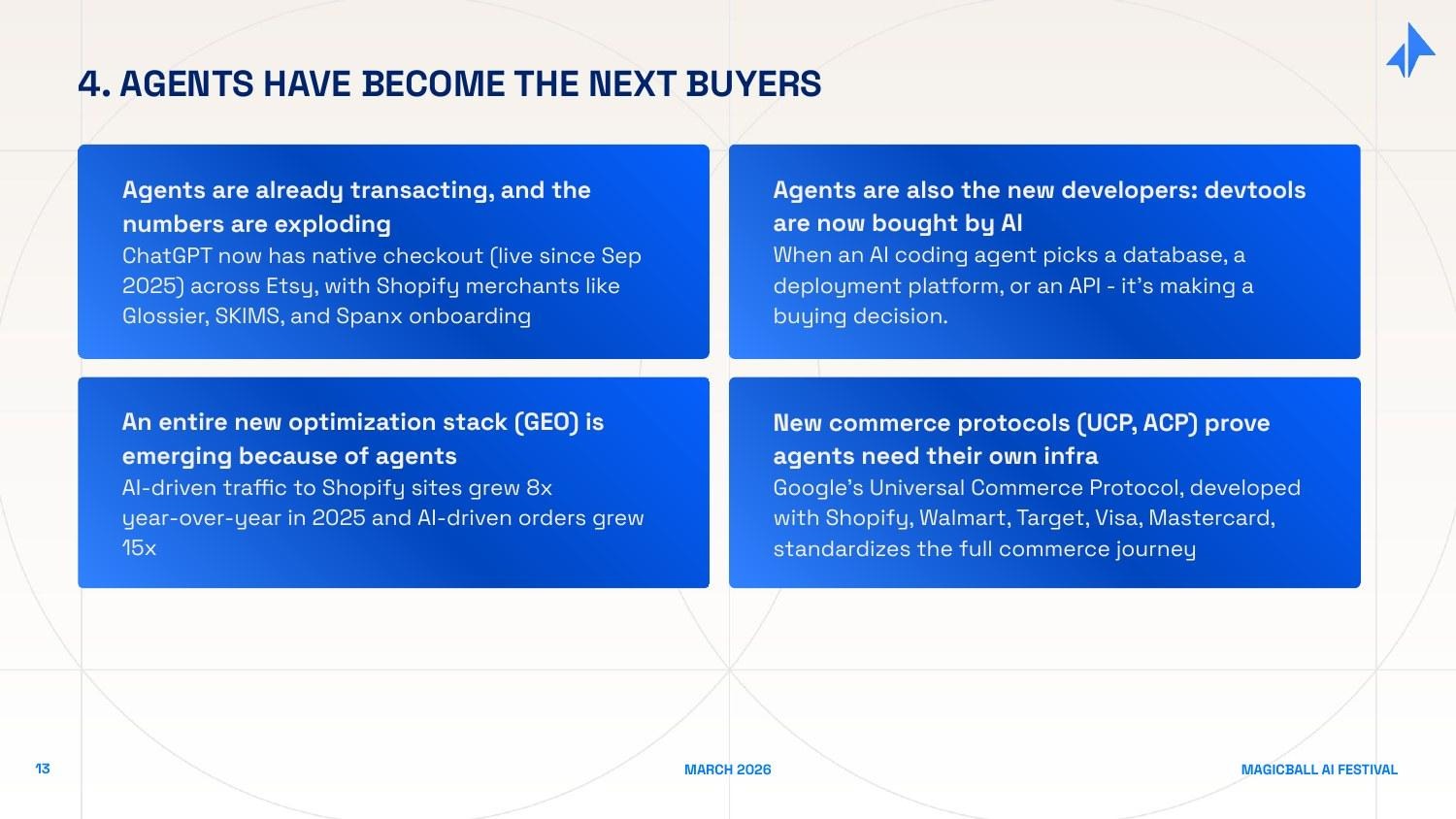
This force is the least obvious, but I think it may be the most transformative over a 5-10 year horizon. AI agents are not just doing work - they are making purchase decisions.
Consider what happens when a developer uses Cursor or Claude Code to build an application. The AI agent, in the course of doing its work, recommends a database, picks a deployment platform, selects monitoring tools, and calls external APIs. These are vendor selection decisions. They are made by the AI, not the developer. The developer may barely notice - they just see working code.
This flips the enterprise go-to-market model. Historically, software was sold to human buyers: CTOs, CIOs, heads of engineering, procurement teams. You won deals through demos, sales calls, analyst reviews, and relationship-building. When AI agents become the actual buyers - or at least the primary influencers - the rules change. An AI coding agent that consistently recommends your database has more influence over developer adoption than any sales team you could hire.
The commerce data makes this concrete. AI-driven traffic to Shopify merchants grew 8x year-over-year in 2025. AI-driven orders grew 15x. ChatGPT has launched native checkout. Google's Universal Commerce Protocol - built in partnership with Shopify, Walmart, Target, Visa, and Mastercard - is standardizing the full AI commerce journey, from discovery to purchase to fulfillment.
An entirely new optimization discipline is emerging in response: Generative Engine Optimization (GEO) - the AI-era equivalent of search engine optimization, focused on making your product and content visible to and preferred by AI agents. The infrastructure for this - agent identity, trust protocols, preference signals, A2A discovery mechanisms - is being built right now.
New open protocols are structuring this landscape: Google's Agent2Agent (A2A) protocol (April 2025) standardizes how agents from different vendors discover and work with each other. Anthropic's Model Context Protocol (MCP, November 2024) standardizes how agents connect to external tools and data. IBM's Agent Communication Protocol (ACP) creates interoperability standards for enterprise agent networks. The middleware layer that builds enterprise-grade trust, routing, and governance on top of these open standards will capture significant value.
Three Opportunity Areas
At Elevation, we are spending a lot of time on middleware and infrastructure layer that can have long term compounding effects.
1. Agent-to-Agent Communication Infrastructure
The enterprise of 2026 is going to run dozens of specialized AI agents—one for HR inquiries, one for supply chain monitoring, one for customer service, one for financial reporting, one for IT helpdesk. The question is: can these agents talk to each other? Today, the answer is almost universally no. And that limitation is the single biggest barrier to AI actually automating enterprise workflows rather than just individual tasks.
Think about a common enterprise workflow: a customer places an unusual order that exceeds their credit limit, requires a component that is currently on backorder, and needs expedited shipping to meet a contractual deadline. Handling this requires the CRM agent, the inventory agent, the finance agent, and the logistics agent to communicate — share context, negotiate priorities, and coordinate on a response. With today's siloed architectures, this requires a human to sit in the middle and relay information. That human is the bottleneck.
The A2A infrastructure layer solves this. Google's A2A protocol provides a standard for how agents discover each other's capabilities and delegate tasks. Anthropic's MCP provides a standard for how agents access external tools and data. IBM's ACP provides enterprise governance on top of agent communication. Together, these open standards are creating the conditions for a multi-agent internet - a network of collaborating AI agents that can accomplish complex, cross-functional workflows autonomously.
The investment opportunity is in the companies building the proprietary orchestration, trust, and governance rails on top of these open standards. Open protocols define the interface; the value is in the implementation - the routing intelligence, the trust management, the observability, the audit logging, the fallback handling that makes multi-agent systems reliable enough for enterprise deployment. This is analogous to how HTTP defined the protocol for the web, but companies like Cloudflare, Akamai, and Fastly built enormously valuable businesses providing the reliability, security, and performance layer on top of it.
2. AI Security
AI security is not one market. It is two distinct, simultaneously expanding markets that share a name.
AI for security means using AI to make enterprise security infrastructure dramatically more effective. The traditional security operations center (SOC) model — human analysts reviewing alerts, triaging incidents, and coordinating responses — is breaking down under alert volume. Modern enterprise environments generate millions of security events per day; human analysts can process a small fraction. AI changes this. Real-time anomaly detection that can identify unusual patterns across the full data estate. Automated incident triage that reduces mean-time-to-respond from hours to minutes. Predictive threat intelligence that identifies attack vectors before they are exploited. Identity and access management that continuously verifies whether behavior matches expected patterns, rather than just checking credentials at login.
Security for AI means protecting AI systems themselves from the novel attack vectors they introduce. Prompt injection - adversarial inputs designed to override an AI's instructions and cause it to take unauthorized actions. Training data poisoning - corrupting the data used to fine-tune models so they behave incorrectly in specific contexts. Model inversion - using patterns in model outputs to reconstruct sensitive training data. LLM red-teaming and safety testing - systematically probing AI systems for failure modes before they are deployed. Data lineage and provenance - tracking what data was used to train or fine-tune a model, and ensuring it meets compliance requirements.
The strategic acquirers are already signaling which direction this is going. Palo Alto Networks acquired Protect AI to strengthen their AI-specific security capabilities. SentinelOne acquired Prompt Security to add advanced controls for generative AI and agentic workloads. These acquisitions tell you that incumbent security vendors see AI security as the next major growth vector - and that they are not confident they can build it internally.
The independent category leaders in both sub-segments are still being built. The companies that establish the standard evaluation framework for AI model security, or the canonical tool for AI-powered SOC automation, will be defining categories rather than joining them.
3. Data Infrastructure for Physical AI
The third opportunity is the one that most people are not yet watching closely, but which I believe will be among the largest infrastructure bets of the decade.
Large language models were built on an internet-scale dataset that took the entirety of human civilization to produce. Every web page, every book, every article, every code repository—decades of human-generated text became the training corpus that made GPT-4, Claude, and Gemini possible. There is no equivalent dataset for physical AI.
Training a robot to navigate a warehouse requires egocentric video - footage of the robot's view as it moves through space, annotated frame by frame. It requires LiDAR point clouds—3D maps of the environment, accurate to centimeters. It requires force and torque sensor data - the physical "feel" of picking up objects with varying weights, shapes, and surface textures. It requires teleoperation trajectories - recordings of expert human operators performing tasks, used for imitation learning. None of this data exists at internet scale. It must be laboriously collected, processed, cleaned, and annotated for each new physical environment and task.
This is not a small problem. The global market for industrial robot installations just hit an all-time high of $17 billion. Amazon has deployed its one-millionth robot across 300+ fulfillment centers and launched a new AI foundation model specifically to improve robotic autonomy. At CES 2026, Jensen Huang declared that "the ChatGPT moment for physical AI is here." Tesla, Figure, 1X, Apptronik, and dozens of other humanoid robotics companies are racing to deploy autonomous systems in factories, warehouses, and logistics facilities.
All of them need data. Specifically, they need the data infrastructure layer that does for physical AI what Common Crawl and The Pile did for language AI - systematic collection, curation, annotation, and distribution of physical interaction data at scale. The picks-and-shovels opportunity here is nascent, poorly understood, and consequently underfunded relative to the scale of the coming demand.
How This Plays Out in Our Portfolio

What I Would Tell a Founder Building in This Space
If you are a founder considering building in the AI middleware layer, here is the framework I use when evaluating opportunities:
- Multi-tenant is the right model. The middleware companies that win will serve many application companies simultaneously, not one enterprise customer at a time. If your product requires extensive customization for each customer, your value is probably in services rather than software. The best infrastructure products are configurable but not bespoke.
- Distribution compounds. The best infrastructure companies become the default - the thing developers reach for first because it is already in every stack they work with. Think about how Stripe became the default payments layer, or how Twilio became the default communications layer. Developer adoption at the bottom of the market creates the enterprise adoption at the top. If your go-to-market requires convincing enterprise procurement teams from day one, you are fighting an uphill battle.
- Data moats compound too. The middleware layer that processes millions of AI interactions per day accumulates a unique dataset - which queries fail, which retrieval strategies work, which routing decisions optimize quality vs. cost, what enterprise AI workloads actually look like. That dataset is an increasingly durable competitive advantage. Build infrastructure that learns from the data it processes, not just infrastructure that moves it.
- Start narrow, expand wide. The best infrastructure companies start by solving one painful problem remarkably well and expand from that base.. Don't try to build the full middleware platform on day one - build one layer exceptionally well, earn the trust of developers, and expand from there.
- The window is real, and it closes. Infrastructure markets tend to consolidate around a small number of dominant players - often one or two for each layer. The companies that get to production quality, developer trust, and enterprise adoption first will have a structurally durable position. This is not a market where the second or third mover can win by being slightly better. Move fast, build to last.


